
You know that moment when you’re learning a new skill, and someone tells you that you’re “doing it wrong” because you’re not following the traditional method? Well, that’s exactly what the AI research field has been facing with teaching machines to think.
Everyone’s been saying you need massive amounts of carefully labeled training data to teach AI anything useful. But what if there was a better way?
This is where DeepSeek-R1 comes in with their groundbreaking research published in January 2025. Their key achievement is creating an AI system that learns to reason primarily through practice and experimentation, while only needing a small amount of initial guidance – just like how humans learn best.

The Solution
DeepSeek’s innovative approach can be understood through three everyday examples:
Learning to Cook Like a Master Chef
Imagine learning to cook. Traditional AI training is like trying to become a chef by memorizing thousands of recipes without ever stepping into a kitchen.
In contrast, DeepSeek’s approach is like starting with just a few basic cooking principles and then spending countless hours experimenting in the kitchen. Sure, you might burn a few dishes at first, but each attempt teaches you something new about how ingredients work together.
A Child Learning to Ride a Bike
Think about how kids learn to ride a bicycle. You don’t start by showing them hours of instructional videos – you give them basic safety tips and then let them practice.
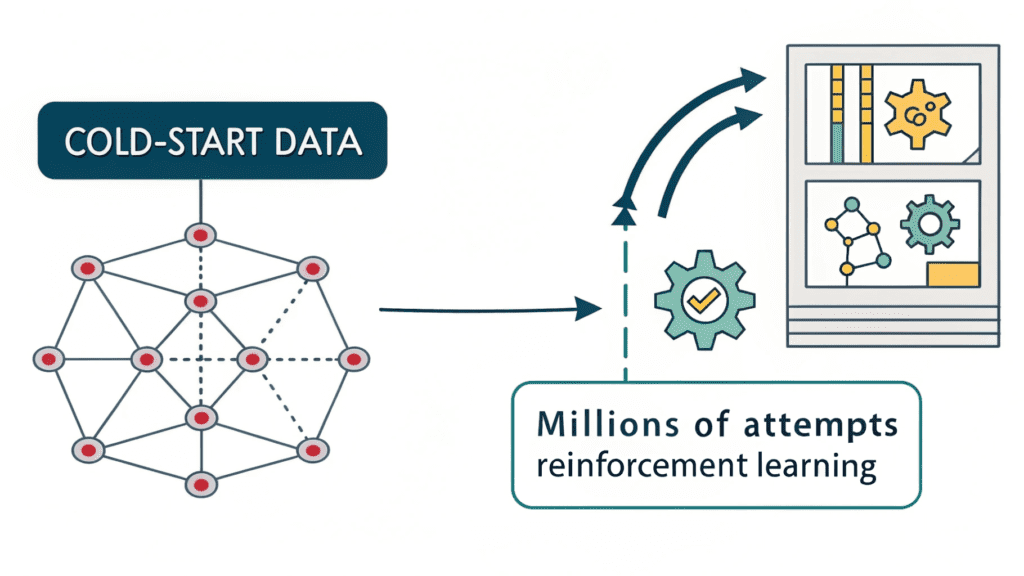
They fall, they get up, they try again, and eventually, they figure it out. This is exactly how DeepSeek-R1 learns: starting with minimal guidance (cold-start data) and then improving through millions of attempts (reinforcement learning).
Mastering Chess Through Play
Consider how modern chess players improve. While they might study some classic games initially, their real growth comes from playing thousands of matches and analyzing their mistakes. Similarly, DeepSeek-R1 begins with a small set of well-chosen examples but develops its expertise through extensive trial and error.
Innovation Highlights
What makes DeepSeek-R1 truly revolutionary is its multi-stage approach to developing reasoning capabilities:
First, there’s DeepSeek-R1-Zero, which proved that an AI could develop strong reasoning abilities through pure reinforcement learning – no supervised training required. Think of it as learning purely through trial and error. While this worked surprisingly well, it had some rough edges, like mixing up languages or producing hard-to-read explanations.
Then came the full DeepSeek-R1, which added a clever twist: starting with a small amount of high-quality examples (cold-start data) before the reinforcement learning phase. This is like giving a student a good foundation before letting them explore independently.
The results were remarkable:
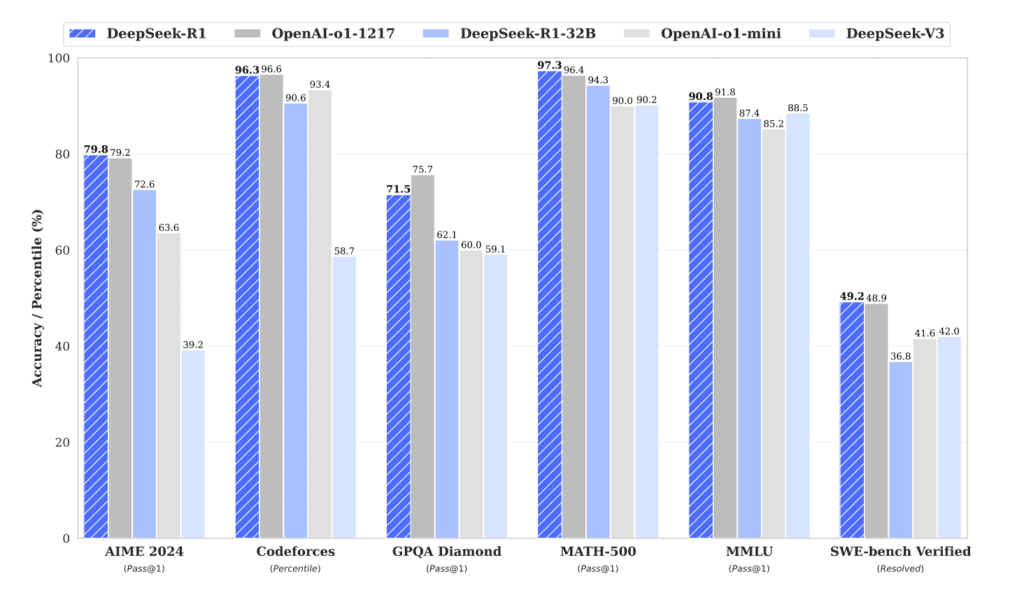
- Achieved 79.8% accuracy on advanced math problems (AIME 2024)
- Matched or exceeded OpenAI’s o1-1217 on many tasks
- Successfully transferred its knowledge to smaller, more efficient models
Future Implications
The success of DeepSeek-R1 points to several exciting possibilities for the future of AI:
Potential Changes:
- More efficient AI training methods requiring less human supervision
- Better ways to combine structured learning with exploration
- More accessible AI through successful knowledge distillation to smaller models
Current Limitations:
- Occasional language mixing in responses
- Sensitivity to prompt formatting
- Room for improvement in software engineering tasks
In Conclusion
DeepSeek-AI’s work feels like a breath of fresh air in the AI world. By teaching machines to learn through trial, error, and a sprinkle of guidance, they’ve created something that mimics how humans grow—by doing, not memorizing.
What’s clear is that this approach points toward a future where AI is smarter, more adaptive, and less resource-hungry. It’s not perfect yet, but it’s a giant leap forward, and honestly, that’s exciting enough.


