
In a significant development during Chinese New Year’s Eve, DeepSeek has officially released Janus-Pro, a groundbreaking multimodal AI model that unifies understanding and generation capabilities. The model and its source code are now fully open-source, marking a major milestone in AI development.
Key Highlights
- Innovative Architecture: Janus-Pro introduces a novel autoregressive framework that decouples visual encoding into separate channels while maintaining a unified Transformer architecture.
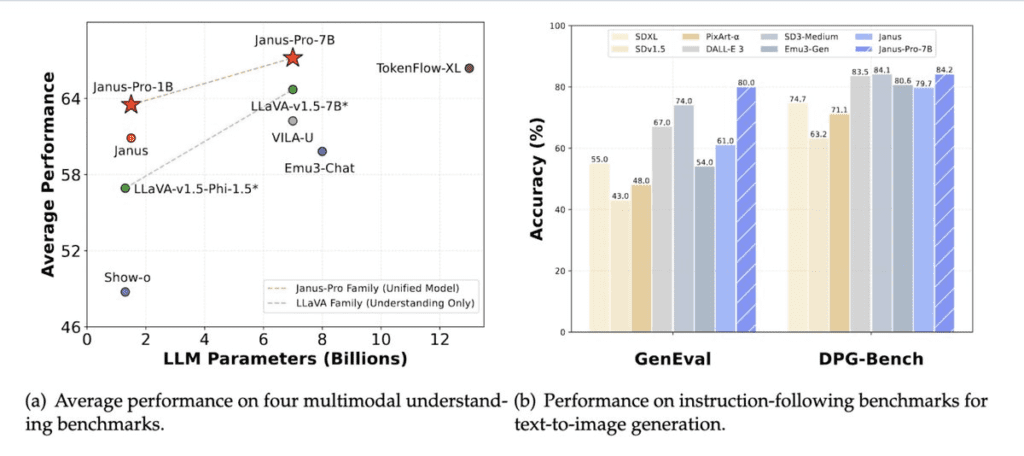
- Impressive Performance: The 7B model achieves a score of 79.2 on MMBench, surpassing competitors like TokenFlow (68.9) and MetaMorph (75.2).
- Efficient Training: Accomplished with minimal computational resources – just 16/32 compute nodes for 7-14 days.
- Browser Compatibility: The 1B model can run directly in browsers using WebGPU.
Technical Breakthroughs
While user testing has shown mixed results in image generation quality, Janus-Pro demonstrates remarkable capabilities in:
- Complex visual understanding tasks
- Detailed image generation from text
- Multi-modal interactions
- Browser-based deployment
Enhanced Training Strategy
Janus-Pro implements significant improvements in three key areas:
- Optimized training procedures
- Expanded training datasets
- Increased model scale capabilities

Architecture Innovation
The model features:
- Decoupled visual encoding for understanding and generation tasks
- SigLIP encoder for high-dimensional semantic feature extraction
- VQ tokenizer for discrete image representation
- Unified multimodal feature processing
Performance Metrics
The model features:
- Text-to-Image: Achieves 0.80 on GenEval, outperforming DALL-E 3 (0.67) and Stable Diffusion 3 Medium (0.74)
- Image Understanding: Sets new benchmarks across multiple evaluation metrics

Current Limitations
- Image resolution currently limited to 384×384
- Some challenges with fine detail rendering, particularly in facial features
- OCR performance affected by resolution constraints
Looking Forward
DeepSeek’s Janus-Pro represents a significant step forward in multimodal AI technology, challenging established players and pushing the boundaries of what’s possible in AI image understanding and generation.
For detailed technical specifications and implementation details, visit:

